In the previous two trigger type scenarios, the data scheduled to be processed is expected to be in a specified location before the pipeline is triggered. An alternative to that is to notify the trigger when the data has been placed into a specific location. When the notification is sent and received, the trigger is fired, and the pipeline activities can access data and perform the necessary ingestion or transformation. If this is a desired scenario, and the data is placed into a storage account, then you can use the storage event trigger type. Figure 6.38 represents the configuration options for this kind of trigger.
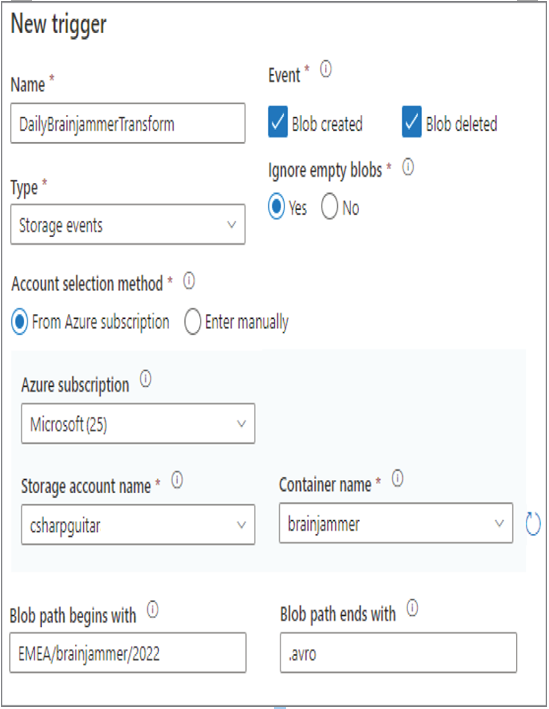
FIGURE 6.38 Azure Synapse Analytics storage event trigger
Notice that you can choose to have the event sent to the trigger based on the Blob Created or Blob Deleted event. This means that when a file is placed into the container on the identified storage account, the trigger is fired and the pipeline executed. The same would be true when a file is deleted from the container and account, in that the pipeline run would be executed. If you expect to receive files that can be empty, and those empty files cause some problem with the pipeline run, you can ignore them by selecting the Yes radio button under the Ignore Empty Blobs header. You can also filter which blobs result in a trigger event by adding values to either the Blob Path Begins With and/or the Blob Path Ends With parameters. In Figure 6.38 you see that the Blob Path Begins With value is EMEA\brainjammer\2022, which means that an event will be triggered when the blob exists in the 2022 folder. Additionally, since there is also a value of .avro in the Blob Path Ends With text box, blobs in the 2022 folder must also end with that file extension. Files that end with a different extension in that same directory will not trigger an event, and no pipeline will be run.