When you attempt to manage something, you must first know in some detail what it is you are managing. In this context, you need to manage a pipeline in Azure Synapse Analytics. Annotations can help you get a quick overview of what your pipelines do. If you open one of the pipelines you have created and select the Properties icon, as shown in Figure 6.68, in addition to the description, you can add an annotation, which links a searchable keyword to the pipeline.
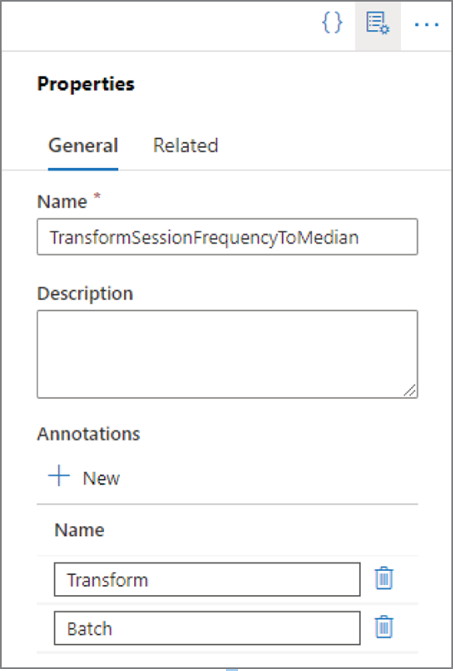
FIGURE 6.68 Manage data pipeline annotations
You can add annotations to pipelines, datasets, linked services, and triggers. You use annotations to search and filter resources. Annotations are similar to tags, which you read about earlier. You can view annotations via the Pipeline Runs page in the Monitor hub, which is covered in Chapter 9. You can also see annotations by using Azure PowerShell with the following snippet. Figure 6.69 shows the result.
Get-AzSynapsePipeline -WorkspaceName “csharpguitar” |
Format-Table -Property Name, Activities, Annotations

FIGURE 6.69 Managing data pipeline annotations using Azure PowerShell
Using that Azure PowerShell cmdlet not only provides the annotations for each pipeline, but you can also get a list of all the activities that run within it, which leads nicely to a good approach to take when you need to manage a pipeline. When managing a pipeline, it is helpful to break it down into smaller pieces, and then determine what needs to be monitored for them to work as expected. You can break a pipeline into activities (see Figure 6.69), data flows, notebooks, SQL scripts, compute pools, etc. Here are some Azure PowerShell cmdlets that can help get better insights into the different components of your pipeline. The following snippet retrieves all the data flows from the targets Azure Synapse Analytics workspace, as illustrated in Figure 6.70.
Get-AzSynapseDataFlow -WorkspaceName “csharpguitar” |
Format-Table -Property Name
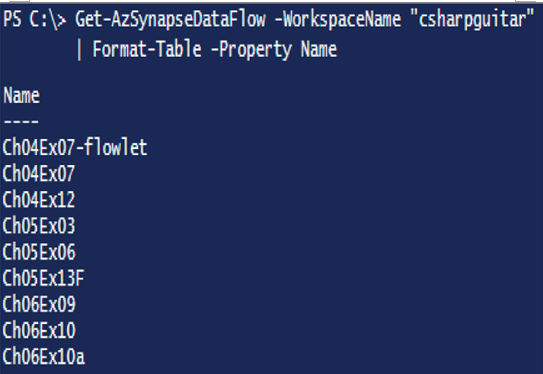
FIGURE 6.70 Managing data pipeline annotations using Azure PowerShell data flow
The following code provides a list of all the notebooks, followed by the cmdlet for listing out the SQL scripts and Spark pools. Figure 6.71 shows the results of the Get‐AzSynapseSparkPool cmdlet which displays the spark pools in the given workspace.
Get-AzSynapseNotebook -WorkspaceName “csharpguitar”
| Format-Table -Property Name
Get-AzSynapseSqlScript -workspaceName “csharpguitar”
| Format-Table -Property Name
Get-AzSynapseSparkPool -WorkspaceName “csharpguitar”
| Format-Table -Property Name, SparkVersion, NodeSize, NodeSizeFamily
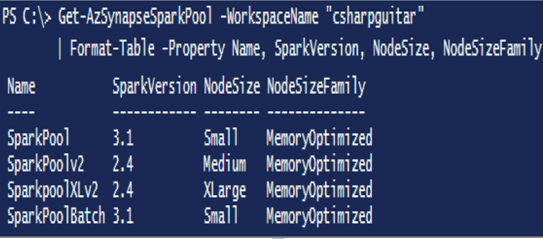
FIGURE 6.71 Managing data pipeline annotations using Azure PowerShell Spark pool
There also exists the option to list datasets, linked services, SQL pools, and all other resources necessary to effectively manage your pipeline.
Manage Spark Jobs in a Pipeline
The following Azure PowerShell cmdlets provide an overview of the Spark job definition activities you have on your workspace:
$pool = Get-AzSynapseSparkPool -WorkspaceName “csharpguitar” `
-SparkPoolName SparkPoolBatch
$pool | Get-AzSynapseSparkJob
$ws = Get-AzSynapseWorkspace -Name “csharpguitar”
$ws | Get-AzSynapseSparkJobDefinition -Name ToAvro
Each cmdlet provides the details about the configuration and existence of Spark jobs in the targeted workspace. The information is available using a browser; however, you need to look at each one individually. If there are many of them, that is not optimal. Instead, you can create a nice report that displays all the information you need. Generally, a Spark job definition activity targets a main definition file, which is typically hosted on an ADLS container. In case of exceptions or pipeline run failures due to this activity, you would first want to make sure this location and the file are where they should be. The cmdlet which retrives the job definition file provided previously is helpful with doing that. The arguments passed to the file and the Apache Spark pool that the job will run on are also important components of managing a Spark job. Chapter 9 discusses monitoring and managing pipelines in more detail.