Another interesting approach for implementing upsert logic is to use what is called a row hash. A very popular hashing algorithm is MD5. This algorithm is no longer secure, but it is useful in this scenario because the focus here is upserting, not security. MD5 cryptography is useful here because it will always return the same hashed value when provided the same input. The implementation begins with identifying which columns you want to hash. Consider that you want to hash the READING_DATETIME and the VALUE columns. The following represents the hashed value of the two identified columns, with the MD5_Hash column containing the hashed value:
If one of the column values on the data changes and an MD5 hash is created, it will be different from the one on the sink. So, part of the logic to determine if the row being ingested requires an update is by comparing the hash values. You can use a Derived Column transformation to add a column to the dataset named columns_hash with a conditional statement like the following:
md5(byNames(split($Columns, ‘,’)))
The value passed to the $Columns comes from a data flow parameter named Columns, which is an array of the columns to hash, as shown in Figure 6.52.
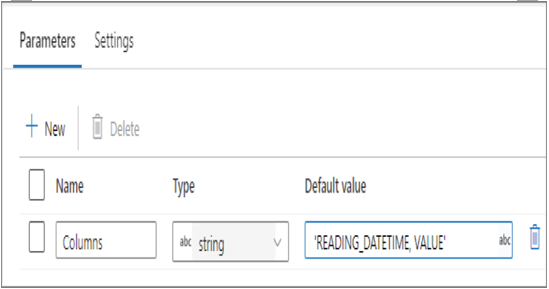
FIGURE 6.52 Upsert data—MD5 Derived Column row hash
Then you add an Exists transformation to check if the columns_hash column on the source and sink match, as shown in Figure 6.53.
If there is a match, the row needs to be updated. If there is no match, the row is new and will be inserted.
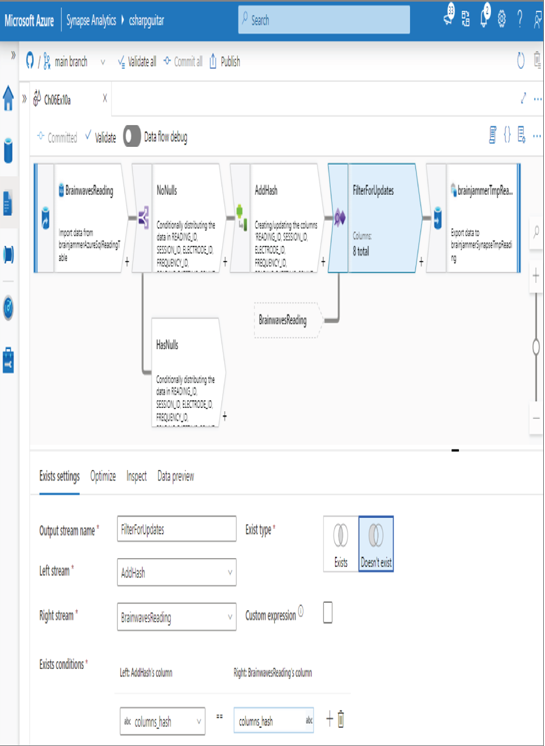
FIGURE 6.53 Upsert data—MD5 Exists row hash
Configure the Batch Size
Combining multiple tasks together and running them has a reputation of making the completion of those tasks happen faster. If you instead perform one task at a time, one after the other, it inherently takes a bit longer. It is the same when working with data. If you send one row at a time from the data source to your data lake, you can imagine the amount of time it could take if there are millions or billions of rows. Alternatively, you can send or retrieve 1,000 or more rows at a time and process them, sometimes in parallel. There are numerous locations where you can configure batch sizes.
Copy Data
There is a Copy Data activity that you can add to an Azure Synapse Analytics pipeline. The Sink tab of the Copy Data activity includes an attribute named Write Batch Size. By default, the platform logic estimates the most appropriate batch size. The default value is based on the size of the row, which is calculated by combining all the columns together on a single row and measuring the total number of consumed bytes. In a majority of cases, using the default setting for Write Batch Size will result in the best performance. However, there may be a scenario that requires some customization and tuning. If you decide to give a specific value for the Write Batch Size attribute, you should also consider modifying the Degree of Copy Parallelism attribute on the Settings tab. By default, the value for the Degree of Copy Parallelism attribute is calculated by the platform logic. This attribute determines how many threads you want the Copy Data activity to read data from the source and copy to the sink in parallel. If optimal performance is not realized by the default algorithm, you can modify and tune these two attributes to find the perfect balance.