Monitoring and troubleshooting pipelines that contain batch loads is covered in more detail in Chapter 9 and Chapter 10. An option for handling a failed batch load is to add a Fail activity to the pipeline. To execute a batch job as part of a pipeline, you know that it runs within a Custom activity. When the Custom activity completes, it produces output that can be referenced using syntax like the following:
@activity(‘<Activity Name>’).output.exitcode
If you connect the Fail activity to the failure path from the Custom activity, you can capture some information about the failure. Figure 6.72 illustrates how this looks.
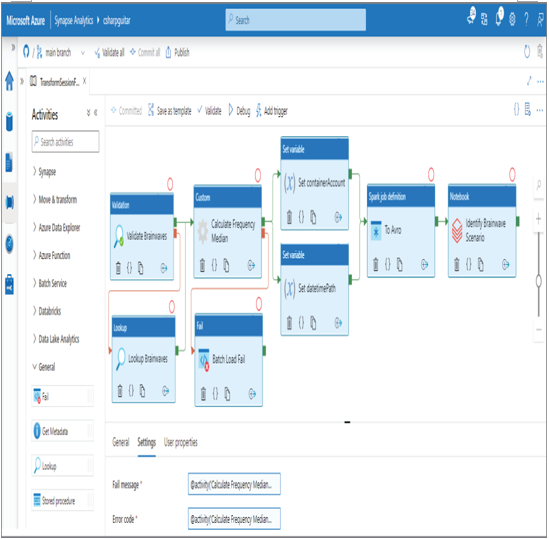
FIGURE 6.72 Handling failed batch loads
The exitcode provides a starting point to further determine the cause of the failure. Using this information can help determine which actions need to be taken. The output of the Custom activity also provides links to the stdout.txt and stderr.txt files, which can be very helpful as well. There is an additional complexity that has to do with data corruption. It is one thing to be alerted about a failed batch load, but where and when in the code path execution did it fail? Did it partially transform data, or did it go rogue and enter some bad data that will cause problems downstream? You have learned a bit about how to manage that situation in this chapter. So, regardless of the complexity, you should have the skill set that helps you respond to this kind of situation.
Summary
This chapter focused on designing and developing a batch processing solution. Your memory was refreshed about the batch layer portion of the lambda architecture and how it is responsible for incrementally loading the data along the cold path into the serving layer. Batch processing, when implemented in an Azure Synapse Analytics pipeline, runs within a Custom activity. The Custom activity is bound to an Azure Batch account that provides the nodes for executing the data transformation logic. There also exists the capability for running batch jobs in Azure Databricks using workflows, jobs, and notebooks. There are numerous approaches for scheduling the execution of batch jobs. Both Azure Synapse Analytics pipelines and Azure Databricks support triggering based on a schedule that uses date, time, and recurrence. Other triggering options, such as tumbling windows, storage events, and custom events, are found only with Azure Synapse Analytics and Azure Data Factory pipelines.
Batch job solutions are notoriously complicated due to the many upstream and downstream dependencies. In addition, handling missing data, duplicate data, and late‐arriving data scenarios requires some special knowledge and procedures. Determining the significance of the missing or duplicate data is an important step in the decision process of whether to delete or correct the data. Using upsert capabilities and incremental loading of data are essential parts of correcting such scenarios.
Validating batch loads using the Validation and Lookup activities is very helpful in determining if the batch process ran as expected. Checking whether the files to be processed exist before processing and that the output files are expected are part of this validation. Managing the batch loads using Azure PowerShell or the Azure CLI provides a quick and simple overview of all your pipelines, datasets, activities, linked services, etc., in a single report. Finally, you learned about Azure DevOps, its many components, and how they all work together to implement CI/CD.
Exam Essentials
Azure Batch. Azure Batch is a high‐performance computing product that offers nodes capable of processing the largest amounts of datasets that exist. When you run batch jobs in an Azure Synapse Analytics pipeline, the data processing takes place on an Azure Batch node. The nodes are highly scalable and can process tasks concurrently and in parallel.
Tumbling window. A pipeline that is scheduled using a tumbling window trigger is done so due to upstream dependencies. Therefore, if the upstream batch job the current batch job depends on is delayed, the batch job will wait and delay its execution until the upstream job is completed.
Event Grid. When a custom event trigger is created and bound to a pipeline, the event that triggers the batch job will come from an Event Grid event. A consumer like a pipeline can sign up to be notified about an event by hooking into an Event Grid topic, while an Event Grid subscription is where the event producer sends the event when it happens.
Upserting data. Upsert capabilities are built into the sink element contained in a Data Flow activity. Once the sink is configured, it is up to the platform to determine if an INSERT or UPDATE statement is necessary to load the data row into the target. You can also manually implement the MERGE SQL command to perform upsert activities.
Incremental data load. You should apply changes only after the initial load of source data into your data lake, which typically contains a large amount of data. This decreases costs, and the amount of data being copied is less, so it happens faster. You can use the last modified date of the file or a watermark to determine which files or data rows need to be included in the incremental load.