The following directory structure should not be something new to you at this point. And perhaps you can already visualize how this directory can be used for the incremental loading of data.
{location}/{subject}/{direction}/{yyyy}/{mm}/{dd}/{hh}/*
Here are some specific examples:
EMEA/brainjammer/in/2022/07/15/09/
NA/brainjammer/out/2022/07/15/10/
A valid option for this approach is to use the Copy Data activity, as shown in Figure 6.60.
The content of the Wildcard folder path could be something like the following code snippet:
@concat(variables(‘outputLocation’), ‘/’,
utcnow(‘yyyy’), ‘/’,
utcnow(‘MM’), ‘/’,
utcnow(‘dd’), ‘/’,
utcnow(‘HH’), ‘/’)
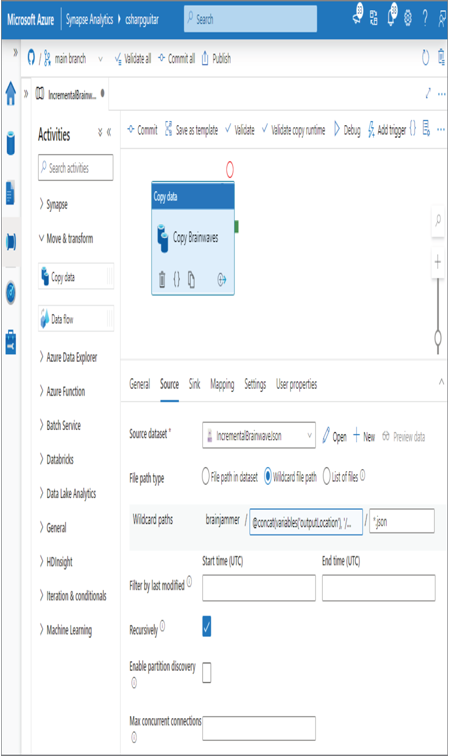
FIGURE 6.60 Incremental data loads—Copy Data activity
This approach can check for newly arriving files on an hourly basis and then copy them from the source to the sink. After the copy, you can perform any transformation using a batch job, notebook, or Spark job.
Integrate Jupyter/IPython Notebooks into a Data Pipeline
Your first exposure to a Jupyter notebook in this book was in Chapter 4. You learned that the Develop hub includes an Import feature that allows you to upload existing Jupyter notebooks, which have the file extension of .ipynb. Chapter 5 covered how to use a Jupyter notebook in Azure Synapse Analytics, Azure Databricks, Azure HDInsight, and Azure Data Studio. Chapter 5 also included two exercises that used Jupyter notebooks, Exercise 5.3 and Exercise 5.4. An example Jupyter notebook named Ch05Ex03.ipynb is in the Chapter05 directory on GitHub. Building on all that, in this chapter you imported and executed an existing Jupyter notebook into an Azure Databricks workspace in Exercise 6.4. Later in that same exercise, you integrated that Jupyter notebook, which converted AVRO files to a delta table in the TransformSessionFrequencyToMedian Azure Synapse Analytics pipeline. The Jupyter notebook for Exercise 6.4, IdentifyBrainwaveScenario.ipynb, is in the Chapter06/Ch06Ex04 directory on GitHub. Finally, in Exercise 6.8 you scheduled a workflow job in Azure Databricks using that same Jupyter notebook. It should go without saying that you know a thing or two about Jupyter notebooks now.