For managing delays in a data streaming scenario, there is a concept known as a watermark. The details are covered in detail in Chapter 7, but as the context here is applicable, it seems like a good place to introduce it. A watermark is a marker that specifies the point at which the ingestion of the stream is located. As the data enters the stream processor, it is given a watermark. If the difference between the watermark and the clock time is greater than zero, there is a perceived delay in the stream processing. Chapter 7 covers the impact of this and how to fix it.
Upsert Data
The act of upserting is useful in scenarios where you are not certain if the data you are ingesting exists on the target sink. As you learned in Chapter 3, the MERGE command is a method for performing an upsert, where an upsert will insert the data into a table if the data does not already exist or update the row if it does. The pseudocode for a MERGE command resembles the following:
MERGE INTO TmpReading
USING updates
ON TmpReading.READING_ID = updates.READING_ID
WHEN MATCHED THEN
UPDATE SET …
WHEN NOT MATCHED THEN
INSERT …
If the TmpReading.READING_ID matches a READING_ID from the updates data injection source, it means the row already exists. When this is the case, the UPDATE statement under the WHEN MATCHED THEN condition is executed. If the updates.READING_ID is not matched, then the data is inserted onto the TmpReading table. In addition to the approach using the MERGE method, you can use an Alter Row transformation in a data flow. In Exercise 6.10 you will use the Alter Row transformation to perform upserts to data residing in an Azure Synapse Analytics dedicated SQL pool. The data flow is shown in Figure 6.48.
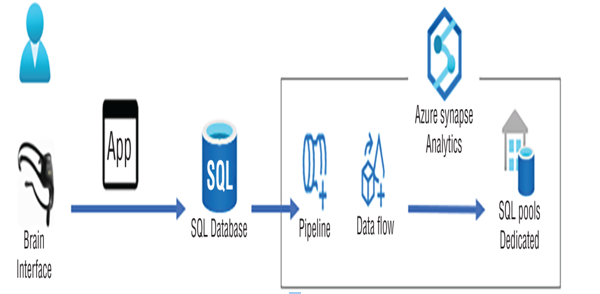
FIGURE 6.48 Upsert data, batching flow diagram
Figure 6.48 illustrates the data being captured from a BCI using a program that stores the data on an Azure SQL database—the one you created in Exercise 2.1. When the pipeline you created in Exercise 5.1 is run, the data flow you will update in Exercise 6.10 will perform the upserts into the SQL dedicated pool you created just before Exercise 3.7.